 Cuadro de Mando con Kylin y Tableau
Cuadro de Mando con Kylin y TableauEl objetivo de esta demo es mostrar como la combinación entre las herramientas Apache Kylin, servidor analítico distribuido sobre Hadoop, y Tableau, herramienta para la exploración y visualización de fuentes Big Data, nos permite la creación y publicación de un cuadro de mando que usa como fuente un conjunto de datos de tipo Big Data.
Los datos usados, relativos al rendimiento académico histórico de una gran universidad, tienen un Volumen suficiente para considerarse Big Data (>100 millones de filas en la tabla hechos).
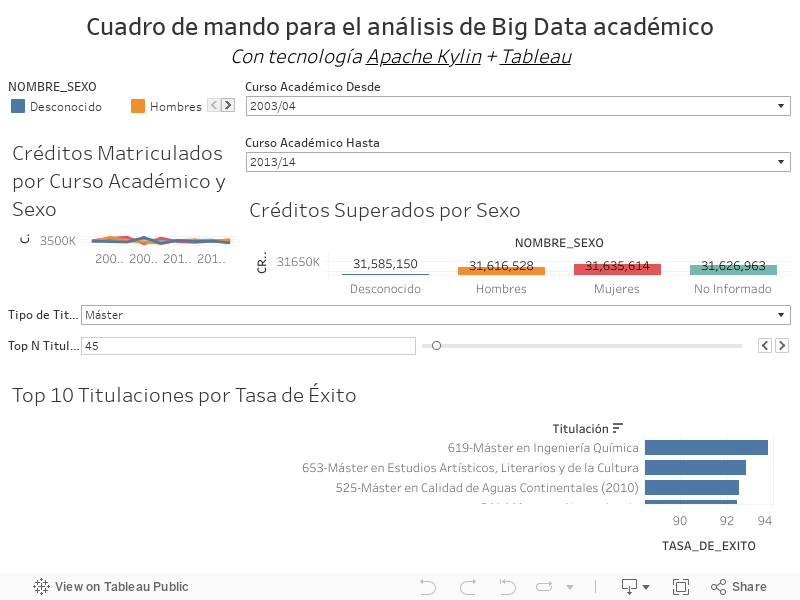
Sobre esta fuente de datos Big Data y mediante el uso de Tableau, hemos creado un cuadro de mando con el que el visitante de esta demo puede interactuar más abajo.

Información
En el caso de estudio que presentamos, hacemos uso de las herramientas Apache Kylin y Tableau para dar soporte al análisis mediante Cuadros de Mando de un almacén de datos (Data Warehouse, DW) que contiene datos con características Big Data (Volumen, Velocidad y Variedad).
Se trata de un gran Volumen de datos académicos, relativos a los últimos 15 años de una universidad de gran tamaño.
A partir de esta fuente de datos, se ha diseñado un modelo multidimensional para el análisis del rendimiento académico.
En él contamos con unos 100.000 millones de medidas cómo los créditos relativos a asignaturas aprobadas, suspendidas o matriculadas.
Estos hechos se analizan en base a distintas dimensiones o contextos de análisis, como el Sexo, la Calificación o el Año Académico.
Dado que este Volumen de datos es demasiado grande para analizarlo con un rendimiento aceptable con los sistemas OLAP (R-OLAP y M-OLAP) tradicionales, hemos decidido probar la tecnología Apache Kylin, la cual promete tiempos de respuesta de unos pocos segundos para Volúmenes que pueden superar los 10 billones de filas en la tabla de hechos o medidas.
Las tecnologías del entorno Hadoop fundamentales para Kylin son Apache Hive y Apache HBase.
El almacén de datos (Data Warehouse, DW) se crea en forma de modelo estrella y se mantiene en Apache Hive. A partir de este modelo y mediante la definición de un modelo de metadatos del cubo OLAP, Apache Kylin, mediante un proceso offline, crea un cubo multidimensional (MOLAP) en HBase. A partir de este momento, Kylin permite hacer consultas sobre el mismo a través de su interfaz SQL, también accesible a través de conectores J/ODBC.
Para lograr la exploración de los datos y generar una visualización que le permita a los usuario extraer información útil de los datos, hemos seleccionados dos herramientas de Tableau: Tableau Desktop y Tableau Public.
En primer lugar hemos usado Tableau Desktop, herramienta comercial, para la conexión con Apache Kylin y la creación de un cuadro de mando similar al que realizamos para el ejemplo con Apache Zeppelin. La herramienta Tableau Desktop facilita la creación y publicación de completos cuadros de mando a los usuarios finales de los datos, arrastrando y soltando las fuentes de datos y gráficos en un lienzo. Podemos ver todo el proceso de creación en el vídeo de la demo.
Finalmente, publicamos nuestro cuadro de mando para compartirlo con el resto de nuestra organización. Si requerimos una conexión en vivo necesitaremos una licencia de Tableau Server o Tableau Online. Sin embargo, podemos optar por crear un extracto de los datos y publicar el cuadro de mando con la herramienta gratuita Tableau Public, como es el caso de nuestro cuadro de mando de ejemplo. El problema si elegimos esta opción es que nuestro cuadro de mando no estará sincronizado en tiempo real con el origen de datos, por lo que los datos no se actualizarán cuando cambiemos los parámetros.
Para más información, se puede consultar la entrada en el blog de TodoBI.

Información
Desarrollada por eBay y posteriormente liberada como proyecto Apache open source, Kylin es una herramienta de código libre que da soporte al procesamiento analítico en línea (OLAP) de grandes volúmenes de datos con las características del Big Data (Volumen, Velocidad y Variedad).
Sin embargo, hasta la llegada de Kylin, la tecnología OLAP estaba limitada a las bases de datos relacionales o, en el mejor de los casos, con optimizaciones para el almacenamiento multidimensional, tecnologías con importantes limitaciones para enfrentarse al Big Data.
Apache Kylin, construida sobre la base de distintas tecnologías del entorno Hadoop, proporciona una interfaz SQL que permite la realización de consultas para el análisis multidimensional de un conjunto de datos, logrando unos tiempos de consulta muy bajos (segundos) para hechos de estudio que pueden llegar hasta los 10 billones de filas o más.
Las tecnologías del entorno Hadoop fundamentales para Kylin son Apache Hive y Apache HBase. El almacén de datos (Data Warehouse, DW) se crea en forma de modelo estrella y se mantiene en Apache Hive. A partir de este modelo y mediante la definición de un modelo de metadatos del cubo OLAP, Apache Kylin, mediante un proceso offline, crea un cubo multidimensional (MOLAP) en HBase. Se trata de una estructura optimizada para su consulta a través de la interfaz SQL proporcionada por Kylin.
De esta forma cuando Kylin recibe una consulta SQL, debe decidir si puede responderla con el cubo MOLAP en HBase (en milisegundos o segundos), o sí por el contrario, no se ha incluido en el cubo MOLAP, y se ha ejecutar una consulta frente al esquema estrella en Apache Hive (minutos), lo cual es poco frecuente.
Por último, gracias al uso de SQL y la disponibilidad de drivers J/ODBC podemos conectar con herramientas de Business Intelligence como Tableau, Apache Zeppelin o incluso motores de consultas MDX como Pentaho Mondrian, permitiendo el análisis multidimensional en sus formas habituales: vistas o tablas multidimensionales, cuadros de mando o informes.
Para más información, se puede consultar la entrada en el blog de TodoBI.

Información
Tableau es una las suites comerciales de Business Intelligence (BI) más conocidas, soportando además la conexión con las fuentes Big Data más actuales como Apache Kylin (nuestra demo), Spark SQL, Hive Hortonworks, Cloudera Hadoop, HP Vertica y con otras fuentes de datos más tradicionales como PostgreSQL o Microsoft SQL Server. La gama de herramientas comerciales de Tableau es la siguiente:
Tableau Desktop: Herramienta local para la exploración visual de los datos y el diseño de los cuadros de mando interactivos. Se trata de una herramienta de las denominadas Self-Service BI, es decir, que su sencillo diseño facilita la creación y publicación de completos cuadros de mando a los usuarios finales de los datos, arrastrando y soltando las fuentes de datos y gráficos en un lienzo, además de a los desarrolladores de nuestro equipo de IT, a quienes también simplifica el trabajo.
Tableau Server: Servidor BI que requiere instalación en nuestra infraestructura para compartir los cuadros de mando creados con Tableau Desktop con el resto de nuestra organización. Permite la conexión en tiempo real con las fuentes de datos, es decir, los cuadros de mando interactivos darán lugar a consultas que se lanzan con los orígenes de datos, estando de esta forma siempre sincronizados con nuestros almacenes de datos.
Tableau Online: Servidor BI en la nube de Tableau, que evita la necesidad de instalar y mantener un servidor de BI Tableau server. Además, de las características de Tableau server, como la conexión en tiempo real con las fuentes de datos, nos permitirá realizar ciertas modificaciones sobre los cuadros de mando creados con Tableau Desktop y, también, llevar a cabo nuevas tareas de exploración de los datos.
Además, aunque se trata de herramientas comerciales, Tableau dispone de 2 herramienta gratuitas:
Tableau Desktop Public: Similar a Tableau Desktop, pero no nos permitirá conectar con Apache Kylin ni otras conexiones ODBC, pues las fuentes de datos quedan limitadas en esta versión gratuita a algunas como Google Sheets, Microsoft Excel, archivos CSV, JSON, estadísticos (SAS, SPSS o R) o espaciales (ESRI shape files, KML, and MapInfo).
Tableau Public: Nos permite compartir los cuadros de mandos desarrollados con Tableau Desktop o Tableau Desktop Public de forma gratuita. Sin embargo, requiere crear y subir un extracto de los datos, pues no soporta la conexión en vivo con las fuentes de datos, de forma que no podremos tener sincronizado nuestro cuadro de mando con los orígenes de datos en tiempo real. Esta es la herramienta que hemos usado para publicar el cuadro de mando de nuestra demo.
Para más información, se puede consultar la entrada en el blog de TodoBI.

Información
Como fuente datos Big Data de esta demo, disponemos de un
gran Volumen de datos académicos ficticios, relativos a los últimos 15 años de una universidad de gran tamaño y por la que han pasado más de un millón de alumnos en este tiempo. A partir de esta fuente de datos, se ha diseñado un modelo multidimensional para el análisis del rendimiento académico.
En él contamos con unos 100.000 millones de medidas cómo la suma de los créditos relativos a asignaturas aprobadas, suspendidas o matriculadas.
Además también nos encontramos con otras medidas derivadas de las anteriores y, por tanto, más complejas como son la Tasa de rendimiento y Tasa de éxito, calculadas a partir de la relación entre Créditos Superados y Créditos Matriculados y de la relación entre Créditos Superados y Créditos Presentados.
No menos importantes son las dimensiones o contextos de análisis en base a los que se analizan las medidas anteriores. Como dimensiones de un solo nivel tenemos el Sexo, la Calificación, el Rango de Edad y la siempre presente componente temporal, el Año Académico. Además, hemos incorporado dos dimensiones complejas, con jerarquías de dos niveles y una mayor cardinalidad, siendo frecuente encontrarnos con dimensiones de esta naturaleza.
Con la dimensión Estudio, podemos analizar los datos agrupados al nivel de Tipo de Estudio (Grado, Máster, Doctorado,...) o profundizar (operación Drill Down sobre la vista OLAP) hasta los distintos Planes de Estudio, esto es, las distintas titulaciones, como "315-Grado en Biología".
Para más información, se puede consultar la entrada en el blog de TodoBI.



