 Web Search
Web SearchRecuperación avanzada de información semántica en la web
Filtros para la búsqueda avanzada en la web
Resultados
Información
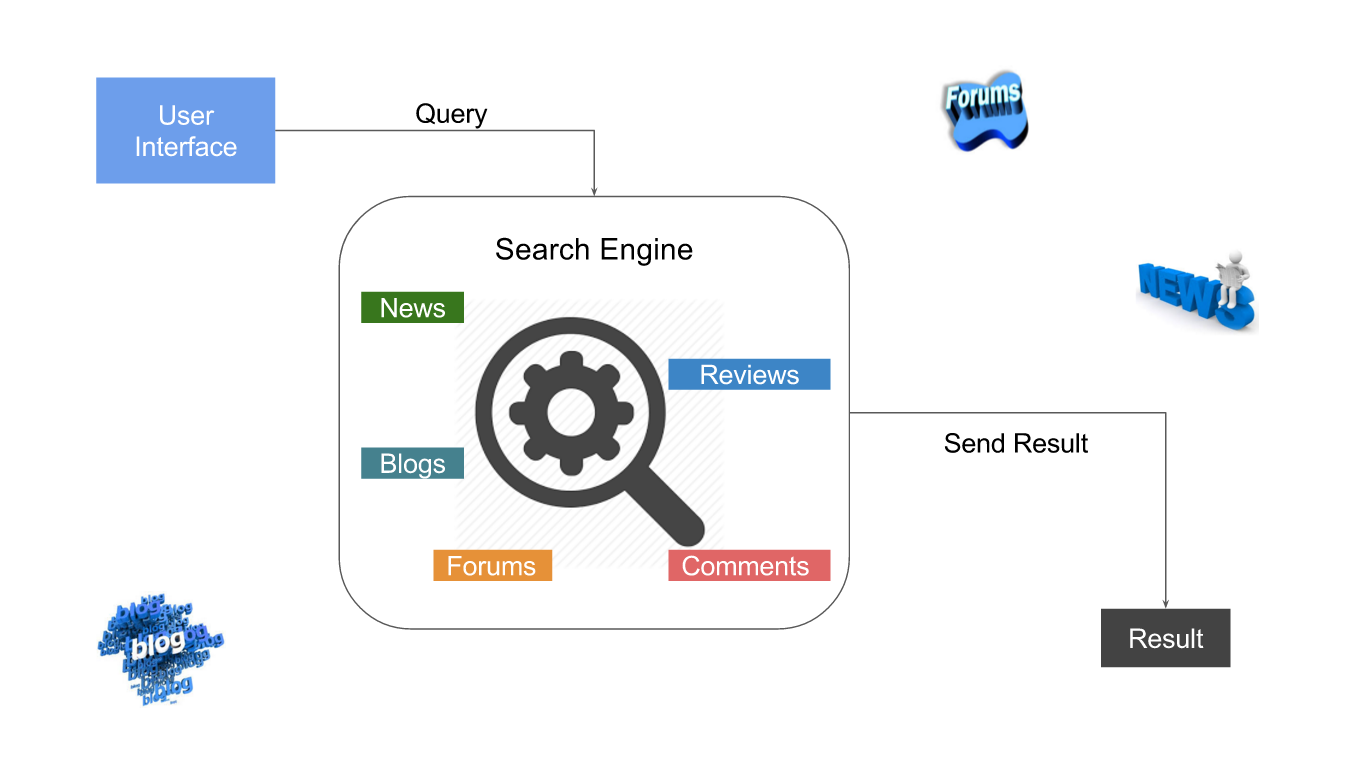
En este ejemplo se ofrece la posibilidad de realizar búsqueda en la web filtrando por varios parámetros.
Hay 3 tipos de sitios en los que se realizan las búsquedas; blogs, forums y noticias.
La implementación se basa en el uso de APIs públicos que realizan búsquedas en distintos sitios, el formato resultante de las fuentes es normalizado a un modelo común, que permite almacenar la información bajo un mismo concepto.
Una de las métricas más interesantes es el "Performance Score" de las informaciones, un valor alto significa un mayor impacto del articulo, con lo cual, filtrando por ese parámetro, se pueden obtener resultados relevantes.
El resultado muestra detalles del articulo o comentario encontrado incluyendo la imagen principal de la página.
Esta solución en complemento con un cluster kafka como se muestra en nuestra demo con kafka puede actuar como un almacén de datos muy interesante en distintos tipos de analítica.
Para información relacionada, puede consultar la siguiente entrada en el blog de TodoBI.



